Using LlamaIndex with Postgres to Build your own Reverse Image Search Engine
A step-by-step guide to build your own Reverse Image Search engine in an Astro application with LlamaIndex and Postgres
Have you ever searched for an image using an... image? Google Images is a widely used example of such reverse image search engine. Do you wonder how it's able to show highly similar images in the search results? Well, in this guide you will learn how to create such an image engine on your own. You will learn how to create a system that's able to index images into a collection, and return images that are highly similar to the uploaded one.
Prerequisites
To follow along this guide, you will need the following:
- Node.js 18 or later
- A Neon account
- A Vercel account
Steps
- Provisioning a Serverless Postgres
- Create a new Astro application
- Enabling Server Side Rendering in Astro with Vercel
- Setting up a Postgres Database Connection
- Build the Image Indexing API Endpoint
- Build the Reverse Image Search API Endpoint
- Build Reverse Image Search User Interface
- Deploy to Vercel
Provisioning a Serverless Postgres
Using Serverless Postgres database helps you scale down to zero. With Neon, you only have to pay for what you use.
To get started, go to the Neon console and enter the name of your choice as the project name.
You will then be presented with a dialog that provides a connecting string of your database. Click on Pooled connection on the top right of the dialog and the connecting string automatically updates in the box below it.
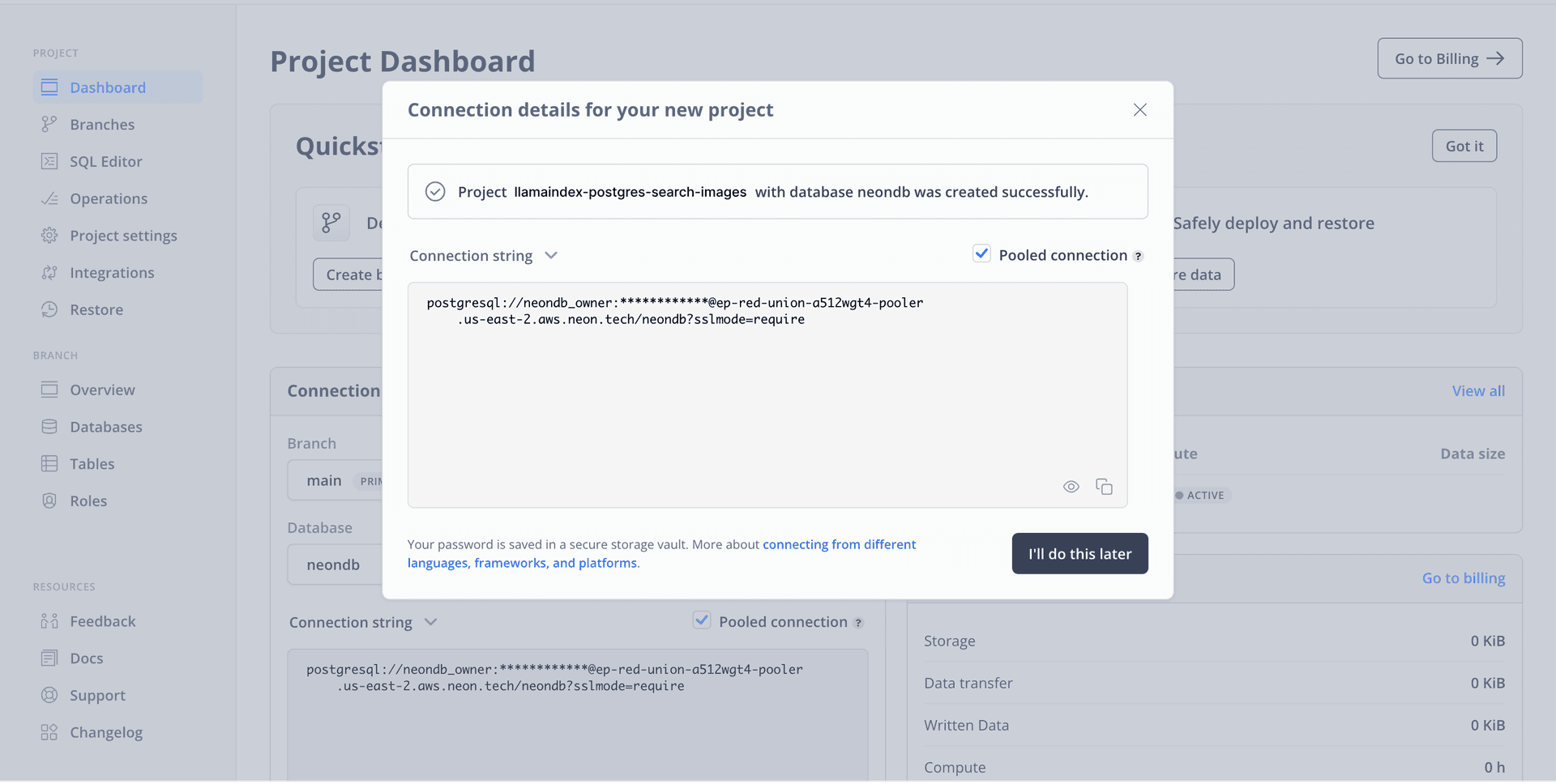
All Neon connection strings have the following format:
postgres://<user>:<password>@<endpoint_hostname>.neon.tech:<port>/<dbname>?sslmode=requireuseris the database user.passwordis the database user’s password.endpoint_hostnameis the host with neon.tech as the TLD.portis the Neon port number. The default port number is 5432.dbnameis the name of the database. “neondb” is the default database created with each Neon project.?sslmode=requirean optional query parameter that enforces the SSL mode while connecting to the Postgres instance for better security.
Save this connecting string somewhere safe to be used as the POSTGRES_URL further in the guide. Proceed further in this guide to create a Astro application.
Create a new Astro application
Let’s get started by creating a new Astro project. Open your terminal and run the following command:
npm create astro@latest my-appnpm create astro is the recommended way to scaffold an Astro project quickly.
When prompted, choose:
Emptywhen prompted on how to start the new project.Yeswhen prompted if plan to write Typescript.Strictwhen prompted how strict Typescript should be.Yeswhen prompted to install dependencies.Yeswhen prompted to initialize a git repository.
Once that’s done, you can move into the project directory and start the app:
cd my-app
npm run devThe app should be running on localhost:4321. Let's close the development server for now.
Next, execute the command in your terminal window below to install the necessary libraries and packages for building the application:
npm install dotenv llamaindex@0.3.4 uuidThe above command installs the following packages:
- dotenv: A library for handling environment variables.
- llamaindex: A data framework for creating LLM applications.
- uuid: A library to generate RFC-compliant UUIDs in JavaScript.
Then, make the following additions in your tsconfig.json file to make relative imports within the project easier:
{
"extends": "astro/tsconfigs/base",
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
}
}
}To complete the initial set up, let's move on to enabling server-side rendering in the Astro application.
Enabling Server Side Rendering in Astro with Vercel
To index and search from images, you are going to require server-side operations to be executed. Enable server side rendering in your Astro project by executing the following command:
npx astro add vercelWhen prompted, choose:
Yeswhen prompted to install the Vercel dependencies.Yeswhen prompted to make changes to Astro configuration file.
The command above installed the following dependency:
@astrojs/vercel: The adapter that allows you to server-side render your Astro application on Vercel.
With this, your Astro application is all set to run in the development mode and deploy to Vercel without changes. Now, let' configure connection to Postgres to index and query from a given set of images.
Setting up a Postgres Database Connection
First, create an .env file in the root directory of your project with the following environment variable to initiate the setup of a database connection:
# Neon Postgres Pooled Connection URL
POSTGRES_URL="postgres://<user>:<password>@<endpoint_hostname>.neon.tech:<port>/<dbname>?sslmode=require"The file, .env should be kept secret and not included in Git history. Ensure that .env is added to the .gitignore file in your project.
Now, let's move on to using Postgres as the vector store to power your image search application with reverse image search capabilities.
Initialize Postgres Vector Store in LlamaIndex
To index and query images (via their vector embeddings), you will use the Postgres-compatible PGVectorStore class by llamaindex. It enables you to write minimal code by extracting image features and creating vector embeddings under the hood. Inside src directory, create a neon.ts file with the following code:
// File: src/neon.ts
import 'dotenv/config';
import { PGVectorStore } from 'llamaindex';
// Create and export a new instance of PGVectorStore
// This instance represents the vector store using PostgreSQL as the backend
export default new PGVectorStore({
connectionString: process.env.POSTGRES_URL,
dimensions: 512,
});The code above begins with importing the dotenv/config, loading all the environment variables into the scope. Further, it exports an instance of PGVectorStore initialized using the Postgres Pooled Connection URL obtained earlier.
Now, let's move on to writing an API endpoint in the Astro application with which you can index the given set of image URLs in your Postgres database.
Build the Image Indexing API Endpoint
LlamaIndex in combination with ClipEmbedding, internally retrieves the remote images, extracts their features using the CLIP model, and generates their vector embeddings. This process involves analyzing various visual and semantic aspects of the image to create a numerical representation that captures its essence. By handling feature extraction and embedding generation, llamaindex enables you to focus on building the rest of your application.
To index images via an API endpoint, create a file src/pages/api/upsert.ts with the following code:
// File: src/pages/api/upsert.ts
import { v4 as uuidv4 } from 'uuid';
import imageVectorStore from '@/neon';
import type { APIContext } from 'astro';
import { ClipEmbedding, ImageDocument, Settings, VectorStoreIndex } from 'llamaindex';
// Set the embedding model to Clip for image embeddings
Settings.embedModel = new ClipEmbedding();
export async function POST({ request }: APIContext) {
// Parse the JSON body of the request to get the list of image URLs
const { images = [] }: { images: string[] } = await request.json();
// Convert image URLs into ImageDocument objects
const documents = images.map(
(imageURL: string) =>
new ImageDocument({
// Generate a unique ID for each image document
id_: uuidv4(),
// Convert imageURL to a URL object
image: new URL(imageURL),
// Attach metadata with the image URL
metadata: { url: imageURL },
})
);
// Index the ImageDocument objects in the vector store
await VectorStoreIndex.fromDocuments(documents, { imageVectorStore });
}The code above begins with importing modules including uuid, llamaindex, and imageVectorStore (an alias for the instance of the PGVectorStore instance created earlier). Further, the code sets the embedding model to Clip for image embeddings. This takes care of extracting features from images, and creating their vector embeddings.
In the POST function, it handles incoming requests, expecting a JSON body with an array of image URLs. It converts each URL into an ImageDocument object, generating a unique ID for each, and attaching metadata containing the original URL.
The ImageDocument objects are then indexed in the vector store using VectorStoreIndex.fromDocuments(), which takes the documents array and options object as parameters. The imageVectorStore is specified as the target store for indexing. The entire process allows for efficient storage (and retrieval) of image embeddings in your application.
With indexing complete, let's move on to building the reverse image search API endpoint.
Build the Reverse Image Search API Endpoint
First, let's walk through the process of reverse image search. A user would upload an image and then you'd need to find similar images. Greater the similarity, higher the priority in the image search results. The common ground for computing similarities between images is a numerical representation of their visual and semantic features. The computation of these features is done via CLIP model (by OpenAI) internally in the LlamaIndex library. LlamaIndex, upon querying would return a set of images along with the similarity score, i.e. how closely are the two images related. This allows you to efficiently handles this similarity search of images based on their embeddings.
To reverse image search via an API endpoint, create a file src/pages/api/query.ts with the following code:
// File: src/pages/api/query.ts
import type { APIContext } from 'astro';
export async function POST({ request }: APIContext) {
// Parse the form data from the request to get the file
const data = await request.formData();
const file = data.get('file') as File;
// If no file is provided, return a 400 Bad Request response
if (!file) return new Response(null, { status: 400 });
// Read the file contents into a buffer
const fileBuffer = await file.arrayBuffer();
// Create a Blob from the buffer with the correct MIME type
const fileBlob = new Blob([fileBuffer], { type: file.type });
// ...
}The code above implements a POST function, expecting a form data request with a file attached. It retrieves and validates the presence of file in the request.
Further, it reads its contents into a buffer using arrayBuffer(), and creates a Blob with the correct MIME type. This allows the API endpoint to accept images directly in the request, saving compute (on the server-side) for fetching remote image URL to search on.
Now with the following code you get to the final set of operations, i.e. creating vector embeddings of the image and returning highly similar images.
// File: src/pages/api/query.ts
// ...
import neonStore from '@/neon';
import { ClipEmbedding, VectorStoreQueryMode } from 'llamaindex';
export async function POST({ request }: APIContext) {
// ...
// Get the image embedding using ClipEmbedding
const image_embedding = await new ClipEmbedding().getImageEmbedding(fileBlob);
// Query the Neon Postgres vector store for similar images
const { similarities, nodes } = await neonStore.query({
similarityTopK: 100,
queryEmbedding: image_embedding,
mode: VectorStoreQueryMode.DEFAULT,
});
// Initialize an array to store relevant image URLs
const relevantImages: string[] = [];
if (nodes) {
similarities.forEach((similarity: number, index: number) => {
// Check if similarity is greater than 90% (i.e., similarity threshold)
if (100 - similarity > 90) {
const document = nodes[index];
relevantImages.push(document.metadata.url);
}
});
}
return new Response(JSON.stringify(relevantImages), {
headers: { 'Content-Type': 'application/json' },
});
}The code above adds two new imports: neonStore (an alias for the PGVectorStore instance) and ClipEmbedding from llamaindex. It initializes the embedding model as Clip for processing image embeddings. It then utilizes the Clip embedding model to extract the image embedding. Further, it queries the Neon Postgres vector store for similar images using the extracted embedding. The query parameters include a similarity threshold and the image embedding.
The relevant images are filtered based on a similarity threshold of 90%, and their URLs are stored in an array. Finally, the endpoint returns a JSON response containing the URLs of the relevant images. This process enables efficient and high quality retrieval of similar images based on their embeddings, completing the reverse image search functionality within the application.
Now let's get to the final aspect of your Astro application, i.e. the user interface.
Build Reverse Image Search User Interface
For the users to interact with your API endpoints, they require two things: an area on the webpage where they can upload the image they want to search similar ones for, and being able to see the search results.
Update the index.astro file in your src/pages directory with the following code to allow them to upload an image to search with.
---
// File: src/pages/index.astro
---
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="icon" type="image/svg+xml" href="/favicon.svg" />
<meta name="viewport" content="width=device-width" />
<meta name="generator" content="{Astro.generator}" />
<title>Astro</title>
</head>
<body class="flex flex-col items-center">
<form class="flex flex-col" id="fileUploadForm" enctype="multipart/form-data">
<input
class="rounded border px-4 py-3"
type="file"
id="fileInput"
name="file"
accept="image/*"
/>
<button id="query" class="mt-3 max-w-max rounded bg-black px-4 py-1 text-white" type="submit">
Query →
</button>
</form>
</body>
</html>The HTML above contains a form element with the id fileUploadForm, which allows users to upload image files. It consists of an input field of type file and a submit button labeled "Query". The form is set to handle multipart/form-data encoding.
To programtically render the search results, you would need to fetch the response from /api/query endpoint and then create img HTML elements on the webpage. Add the following JavaScript to your index route.
---
// File: src/pages/index.astro
---
<html lang="en">
<head>
<!-- Head -->
</head>
<body class="flex flex-col items-center">
<!-- Form -->
<script>
document.getElementById('fileUploadForm')?.addEventListener('submit', async function (event) {
event.preventDefault()
// remove the previous search results
document.getElementById('searchResults')?.remove()
// create a new form data object that contains the uploaded file
const formData = new FormData()
const fileInput = document.getElementById('fileInput') as HTMLInputElement
if (!fileInput || !fileInput.files || fileInput.files.length === 0) return
formData.append('file', fileInput.files[0])
// query for similar images
const queryCall = await fetch('/api/query', { method: 'POST', body: formData })
const queryResp = await queryCall.json()
// create the search results div
const searchResultsDiv = document.createElement('div')
searchResultsDiv.setAttribute('id', 'searchResults')
// append all the image results to the search results div
queryResp.forEach((eachImage: string) => {
const img = document.createElement('img')
img.setAttribute('class', 'size-100')
img.setAttribute('src', eachImage)
searchResultsDiv.append(img)
})
document.body.append(searchResultsDiv)
})
</script>
</body>
</html>The code above adds an event listener that is invoked in case the form is submitted. Upon submission, it extracts the uploaded file, creates a FormData object containing the file, and sends a POST request to /api/query with the file data.
The response from the query API is received and parsed as JSON. A new div element is dynamically created to hold the search results, and each image URL from the response is used to create an image element, which is then appended to the search results div.
The resulting search results, consisting of dynamically generated images are then visible to the users. This approach enables real-time querying and display of similar images based on the user upload(s).
With all that, your Astro application is ready to be deployed on Vercel with ease.
Deploy to Vercel
The repository is now ready to deploy to Vercel. Use the following steps to deploy:
- Start by creating a GitHub repository containing your app's code.
- Then, navigate to the Vercel Dashboard and create a New Project.
- Link the new project to the GitHub repository you've just created.
- In Settings, update the Environment Variables to match those in your local
.envfile. - Deploy.
Summary
In this guide, you learned how to build a reverse image search engine in an Astro application using LlamaIndex and Serverless Postgres Database. During the process, you learned how to create vector embeddings of the images using ClipEmbeddings, to index and search from them using LlamaIndex Postgres vector store.
Need help?
Join our Discord Server to ask questions or see what others are doing with Neon. Users on paid plans can open a support ticket from the console. For more details, see Getting Support.